世界杯全球运动用品供应平台 模子也需要「睡觉」? CMU新论文让LLM在梦中「巩固缅念念」

机器之心剪辑部
很长一段期间,「长高下文」一直是各大模子厂商武备竞赛的焦点,从 128K 到 1M,再到更长的高下文窗口,业界已然变成一个固有领会,独一窗口弥漫大,模子就能记取更多内容,也就能处罚更长、更复杂的任务。
但问题也随之而来:高下文越长,KV Cache 越肥胖,不仅导致显存一会儿被「吃光」,推理速率愈发冉冉,老本也速即飞腾。
更要津的是,把更多 token 放进窗口,并不等于模子果真把这些信息涟漪成了可推理的长久缅念念,结果是,榜单分数越刷越高,可在一些需要「深度脑暴」的复杂推理任务中,模子常常因为「记不住细节」,频频翻车……
濒临这一两难问题,近日,卡内基梅隆大学(CMU)妥洽马里兰大学等在一篇新论文中建议了有有趣的视角:既然东说念主类筹议职责深入会变笨,大模子也一样,既然如斯为什么不让 LLM 睡一觉呢?

这篇论文的题目提纲振领,《Language Models Need Sleep》,也即是《谈话模子需要睡觉》。
虽然,这里的「睡觉」不是果真睡觉,更准确地说,是一种肖似睡觉的「缅念念巩固机制」。
作家以为,基于 Transformer 的大谈话模子正越来越多地被用于长程任务,然则,其详实力机制在濒临更长高下文时彭胀性较差。为此,他们究诘出了这一「缅念念巩固机制」:
在睡觉过程中,模子会对累积的高下文实验 N 次离线递归前向传播,并通过一种学习得到的局部规则,更新其景况空间模子(SSM)模块中的快速权重(fast weights)。在推理阶段,这种措施把特地贪图改造到「睡觉」阶段,同期保握模子在「醒着」进行掂量时的蔓延不变。
换句话说,它不是让模子一直把通盘内容摊在目下,而是让模子学会在某些节点「停驻来念念一念念」,把刚刚读过的内容消化成之后还能调用的里面景况。

作家在一系列受控的合成任务上测试了该措施,包括细胞自动机、多跳图检索,以及一个更靠拢实在场景的数学推理任务。在这些任务上,粗莽 Transformer 和 SSM-attention 羼杂模子王人会失败,而加多模子的「睡觉」时长 N ,可以栽种性能,其中在需要更深层推理的样本上,栽种最为显然。
接下来,咱们来详备了解一下。
从动物睡觉中获取启发
这篇论文的灵感,来自动物睡觉中的缅念念巩固过程。
2026世界杯官方指定中国区认证平台神经科学的究诘以为,动物从短期缅念念到长久缅念念的改造,是受到海马体 replay 机制的相沿,尤其是在睡觉时刻。在这一阶段,短期的海马体缅念念会被再行激活,并巩固到皮层突触权重中。睡觉会让动物无法对外部刺激作出反应,这也阐明睡觉必须带来弥漫大的领会收益,才值得付出这一代价。
基于这一领会,作家建议了这种把高下文窗口缅念念改造到握久权重中的措施,即当模子的高下文窗口在推理过程中被填满时,模子就会干预「睡觉」景况:对累积的高下文实验屡次前向传播,并通过学习得到的局部规则递归地更新 fast weights,在这个阶段,模子不会采纳外部输入 token。
巩固完成后,高下文窗口会被清空,模子则带着更新后的 fast weights 连接运行。在查考过程中,模子通过通盘过程的反向传播进行端到端优化,以最大化睡觉之后的任务阐扬。
也即是说,大模子的查考过程被差异为两个阶段:
「醒着」阶段:只精采快速反应,世界杯全球运动用品供应平台模子就像粗莽的 Transformer 一样闲居职责,它采纳长文本输入,快速给出掂量和复兴,这时候它不需要对信息进行深度内化,只管「读」和「答」。
「睡觉」阶段:每隔一段期间,模子就会干预「离线睡觉景况」,时刻模子会独揽挑升的后台期间,对积贮的高下文进行 N 次周而复始的离线处罚(Recurrent passes),快要期高下文中的要津细节,涟漪为握久的 fast weights,并写入其景况空间模子(SSM)模块中。
具体如下。
当高下文窗口被填满、模子行将从详实力层中淘汰 token 之前,模子会先干预一个「巩固阶段」,在这一阶段实验递归贪图,通过这种方式彭胀贪图量来处罚深度推理任务,关于较大的 期间步 t,仍然得志掂量阶段的蔓延不断。
举例,如果在沿路 D 个模块上进行轮回,其样式如下:
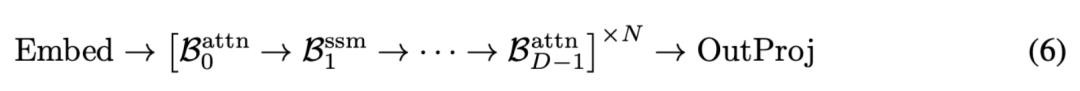
其中,N 默示在通盘架构上轮回实验 N 次传递。
下图对架构进行了详备描摹,从一个 SSM-Attention 羼杂模子运行化,该模子具有固定的高下文窗口大小 L,其中详实力缓存每 L 个 token 就会被全王人淘汰。在每 L 个 token 淘汰 KV Cache 之前,模子会实验 N 次递归传递,字据底下的公式 3 迭代更新 SSM 模块里面的快速权重;当 N = 1 时,它就退化为一个粗莽的 SSM-Attention 羼杂模子。模子在迭代更新快速权重的这一阶段即是「睡觉阶段」。
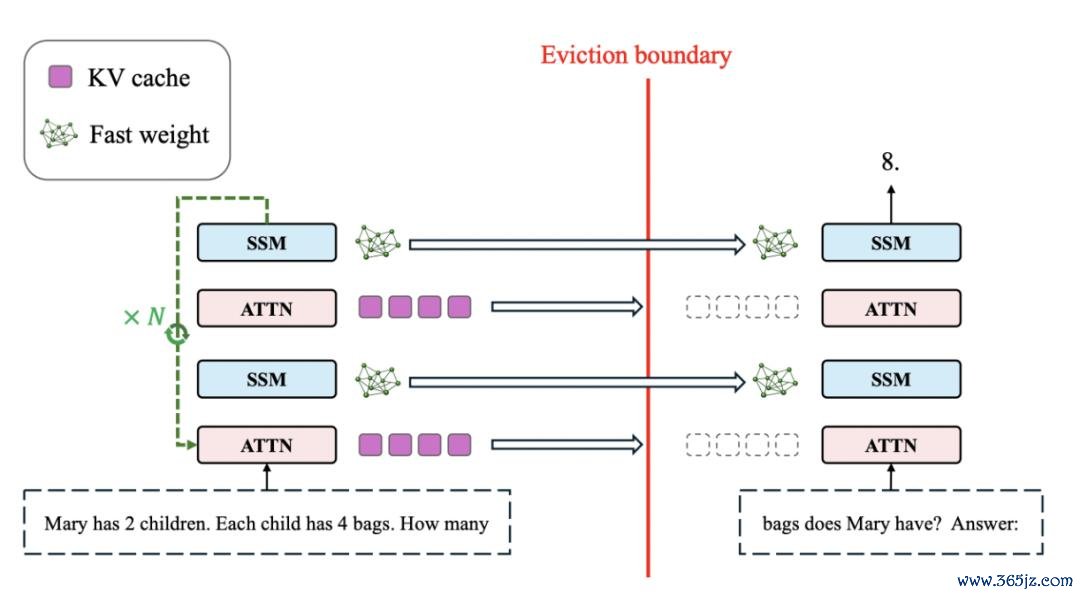

在递归式地细化快速权重之后,KV Cache 会被淘汰,模子随后处罚接下来的 L 个 token。
在竣工高下文处罚完结后,模子会基于一经细化后的缅念念和现时高下文,通过一次前向传播来掂量谜底。查考时,模子通过对公式 6 所示的通盘贪图图进行反向传播,最小化掂量极端,这小数与其他深度递归模子肖似。
不同的是,以往的深度递归模子中,梯度会流经递归细化后的特征向量;而在这里,由于睡觉阶段实现后,细化后的特征会被丢弃,梯度骨子深奥经的是被细化后的快速权重。
竣工的查考历程如下所示:

实验:睡得越久,推理越强?
为了考证:加多睡觉时 N,到底能不可栽种模子对「旧」高下文的推理才气?作家进行了系列实验。底下咱们来看一个更接近当然谈话的数学推理任务 GSM-Infinite。
GSM-Infinite 可以剖析为一个长高下文数学推理基准,它融会过添加干豫 token 拉长题目,同期用所需算术操作数松手难度。题目越复杂,需要的推聪敏力越多。
作家在 Jet-Nemotron 2B 和 Ouro 1.4B 两个预查考模子上测试了模子的「睡觉」机制。
结果呈现出一个了了趋势,题目越难,「睡觉」带来的栽种越显然:
关于 Jet-Nemotron 2B,6 次 sleep loop 将 6 步运算题准确率从 0.742 栽种到 0.812,将 8 步运算题从 0.351 栽种到 0.388;
关于 Ouro 1.4B,4 次 sleep loop 将 6 步运算题准确率从 0.419 栽种到 0.615,将 8 步运算题从 0.210 栽种到 0.272。
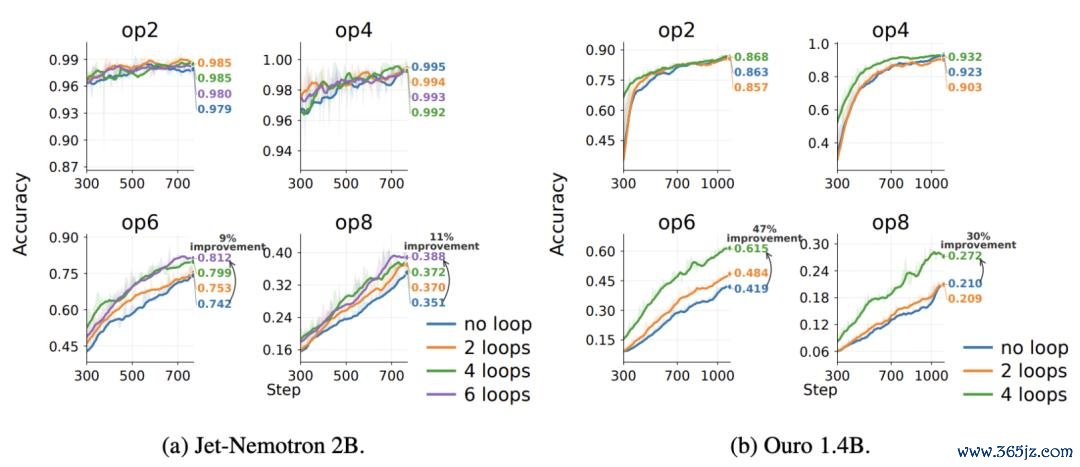
也即是说,「睡觉」机制对浮浅题的匡助相对莫得那么显然限,因为模子原来就能作念得可以;但当任务变得复杂,需要更多步推理、更强的高下文组织才气时,「睡觉」阶段的特地贪图就起先阐扬作用了……
局限性:后果显然,代价相通显然
虽然,这篇论文并莫得把问题说得过于乐不雅。
作家坦言,这种措施是通过把特地递归贪图改造到巩固阶段,保握了掂量阶段的单次前向传播蔓延。但可这种收益不是免费的:在查考过程中,需要实验 N 次更深的前向和反向传播,这会让查考变慢,也可能变得不持重。
而实验 N 次,带来后果显然栽种是真,查考老本随其线性增长亦然真……
因此,这项职责现在仍主若是措施论探索。
作家默示,这一措施主要孝敬是措施论层面的,况且评估主要基于受控合成任务和中等界限预查考模子。现在,它还不是一个一经在超大界限商用模子、实在长程 Agent 系统中充分考证的熟识决策。
更多细目世界杯全球运动用品供应平台,可稽察论文了解!